The Ruby Language Binding
- Joining Two Worlds: Ruby and C++
- Lifetime management
- Transfer Of Ownership And Object Lifetime
- Static And Local Methods, Access
- Data types, Arguments and Return values
- Implicit conversions
- Constness
- Reimplementing Virtual Methods
- Iterators
- Exceptions
- Events
This article covers the basics of the Ruby binding provided by KLayout. The Ruby binding is basically a way to access the native code classes of KLayout through a Ruby interface. KLayout is written in C++, hence the topic covered here is the interface between C++ and Ruby objects. The Ruby API (RBA) is based on the Ruby binding of a selection of C++ classes. RBA is also the framework that implements the Ruby side of the binding. The C++ side is a more generic form which is not strictly confined to a certain programming language. The C++ side of the framework is referred to as GSI (generic scripting interface) in the KLayout sources.
Joining Two Worlds: Ruby and C++
The usual and most simple case of a Ruby/C++ binding is a Ruby wrapper over a C++ object. When Ruby code likes to access a C++ object, the first thing that happens is that a Ruby proxy object is created that is linked to the C++ object. That link can be unidirectional (the Ruby object knows about the C++ object, but the C++ object does not know about the Ruby object) or bidirectional (each know of each other). The kind of linking is important because a bidirectional link is stronger than a unidirectional link and allows lifetime tracking of the other object. For performance reason, not all objects implement the ability of bidirectional links, in particular not the ones that live in the layout database. That has certain consequences we will discuss in the lifetime management section below.
The Ruby proxy object serves as a connection point to the C++ object. It defines methods that correspond to methods in the C++ object. When one of these methods is called, their implementation collects the arguments of the method call and converts them to a binary representation that C++ understands. That process is usually called marshalling. Having done so, the execution continues in C++ space where the GSI framework will use the binary representation of the arguments to call the target method of the C++ object. After the call has returned the same happens on the way back, this time with the return value instead of the arguments. Having converted the return value back into Ruby objects the execution returns to the Ruby script.
The following image illustrates the relationship:
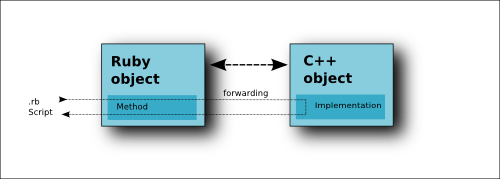
While that operation is simple in theory there are some pitfalls when implementing that scheme. One of them is the inherent compatibility issue between C++ and Ruby's lifetime management. In Ruby, the interpreter knows about all references to a Ruby object. When there are no more references to an object, the object is marked as "no longer used" and deleted. In other words: as long as any reference exists, the object is valid and a reference will never become invalid.
In C++, it is responsibility of the code to explicitly delete an object when it is no longer used. In other words: as long as any reference exists, the object is valid and a reference will never become invalid. Often there is a clear ownership: an object belongs to another object which controls the lifetime of the owned object (aggregation). That scheme is more efficient and predictable but it bears the danger of holding references to objects which are deleted already.
That raises the question how the lifetime of the Ruby proxy object is controlled and how the lifetime of the C++ object is related to that.
Lifetime management
RBA/GSI follows a simple principle that significantly simplifies the implementation: who created an object is responsible for cleaning it up. In other words: a ownership of an object is usually not transferred between C++ and Ruby space. Thus we have to consider two cases: The object is created in Ruby or the object is created in C++ code. Literally the object "lives" in Ruby space or in C++ space. In both cases, there is a pair of objects, but one of them is controlling the other.
Case 1: The object lives in Ruby space
When the object is created in Ruby, the Ruby proxy owns the C++ object and when the Ruby object goes out of scope, not only the Ruby object but also the C++ object is deleted. That means, that except if that case is handled by special measures, a reference to such an object must not be stored in C++ space, because we will never know when Ruby will delete the object. A reference can be passed safely as an argument of a method however, provided the method does not store the reference somewhere.
But then: how do we then permanently store an object we have created in Ruby? The answer is simply by creating a copy on the C++ side. That is exactly what happens in that piece of code:
# creates an object that lives in Ruby space: box = RBA::Box.new(0, 0, 10, 20) # insert creates a copy of the box: cell.shapes(layer).insert(box)
That is not an option for heavy objects such as layouts. If such objects need to be stored in C++ space, they are not created in Ruby code. Instead, several methods are provided to create objects that live in C++ space. For example a LayoutView object is not created in Ruby, but rather created inside the MainWindow object with create_layout. After that, the reference is obtained with MainWindow::current_view or MainWindow::view.
An exception to the lifetime control rule given above are Qt objects: a common pattern is to create Qt objects and add them to a container (i.e. widgets to a dialog). This implies a lifetime control transfer from Ruby to C++. RBA handles that case by explicitly transferring control when a QObject or one of the derived objects is created with a parent reference in Ruby code. Qt implements its own mechanism of controlling the lifetime which includes monitoring of the lifetime of child objects. This feature makes transferring the control feasible for these kind of objects. For some Qt methods which are know to transfer the ownership of an object, the ownership is transferred explicitly.
An object living in Ruby space can be explicitly deleted to free resources for example. For this, the "_destroy" method is provided. This method will only deleted the C++ object and not the Ruby object. However, the Ruby object will become invalid and calling a method on such an object will result in an error.
Case 2: the object lives in C++ space
In that case, the Ruby proxy object simply acts as a pointer to a C++ object. An issue arises when the Ruby object is still alive but the C++ object is deleted. In that case, the flavor of the link between the Ruby proxy and C++ object is important: if the link is bidirectional, the C++ object will inform the Ruby proxy that the reference will become invalid. The Ruby proxy will mark itself as being invalid and will block further calls to methods. Object supporting this reference binding are the API classes and "bigger" database objects such as Cell or Layout.
For example:
main_window = ... # the RBA::MainWindow object # returns a reference to a RBA::LayoutView object living in C++ space: view = main_window.current_view # deletes all views and also the object we have a reference to main_window.close_all # this will fail, because the view is a Ruby proxy that knows that the C++ object # has been deleted: view.load_layout(...) # You can check this by asking "_destroyed?". This will return "true": view._destroyed?
For "lightweight" objects such as the geometry primitives (Box, Polygon etc.), the link is unidirectional and lifetime monitoring is not possible. This situation bears the danger of invalid references with fatal consequences if an attempt is made to call a method then. Fortunately this case is rare and usually mitigated by providing an object clone.
Calling "_destroy" on an object living in C++ space is not safe in general. In some cases, this can have fatal consequences (i.e. destroying the MainWindow object). An exception from that rule are Qt objects because Qt does lifetime monitoring internally and destroying an object from the outside (Ruby) is a valid operation in most cases (although there are exceptions).
Transfer Of Ownership And Object Lifetime
Some C++ methods accept pointers to objects and take over ownership over this object. This happens specifically inside the Qt methods. In that case, the Ruby object has to release ownership over that object. For example, "QApplication::postEvent" takes over the ownership over the event object passed to it and will finally destroy this object:
event = RBA::QKeyEvent::new # takes over ownership over the event object: RBA::QApplication::postEvent(RBA::MainWindow::instance, event) ... # later on, when "event" goes out of scope, the GC will try to # delete the QKeyEvent object and without further provisions, the # application will crash!
Luckily, there are such provisions. The "postEvent" method is tagged specially, so the interpreter knows that it has to transfer ownership of the event object to Qt.
If that was not the case, one could use "_unmanage" to mark the event object no longer being managed by the script:
event = RBA::QKeyEvent::new event._unmanage # Now, somebody else is responsible for managing the object's lifetime
The reverse is true for methods delivering new objects which the Ruby interpreter is supposed to manage. For example "QLayout::takeAt" returns a free objects which the caller is responsible for deleting. Without further provisions this would lead to a memory leak, because Ruby does not delete the borrowed object:
layout = ... # A RBA::QLayout object child = layout.takeAt(0) # later on, when child goes out of scope, Ruby needs to delete the object. # Here is does, because it knows that "takeAt" delivers a free object.
If the declaration of "takeAt" was not aware of the return mode, one could use "_manage" to mark the event object as to be managed by the script:
obj = createObjectForMe() event._manage # Now, when event goes out of scope, the object will be destroyed too.
Static And Local Methods, Access
Static C++ methods is simply implemented as class methods while local methods are implemented as instance methods.
RBA also supports binding of protected methods. A Ruby class derived from a C++ class exposed to Ruby can call those methods while code outside that class cannot access those methods. Public methods can be called from anywhere.
Data types, Arguments and Return values
Ruby and C++ feature different types of data. While in Ruby, a variable is of any type, in C++ a variable has a fixed type. This also is the case for arguments of methods and return values. A C++ method requires an argument to be of a certain type. In addition, C++ features pointers, references and a variety of containers. Therefore a mapping of Ruby types to C++ types is required. The following table summarizes the mapping for the simple types:
| C++ | Ruby | Comment |
| (signed, unsigned) char, int, short, long, long long | FixNum | |
| float, double | Float | |
| const char *, std::string, QString, QByteArray | String | KLayout uses UTF-8 encoding for std::string. Binary strings can be passed to and from QByteArray. |
| bool | nil, true, false | When passing a Ruby value to a bool parameter, the Ruby's nil and false values are converted to false. All other values are converted to true. This follows the usual Ruby semantics. |
| void * | FixNum | Passing pointers between Ruby and C++ is not possible. But often, a "void *" value is used as a handle or as an arbitrary value. The Ruby binding allows storing of such values as FixNum. |
| QVariant, tl::Variant (KLayout) | any | Any simple Ruby type that can be mapped to a C++ value can be stored in a QVariant. tl::Variant also supports a selection of complex types (i.e. RBA::Point, RBA::DPoint, RBA::Box, RBA::DBox etc.). |
Arguments that expect objects of classes known to RBA can be passed references from Ruby objects. The linear containers (std::vector, QList etc.) are mapped to Ruby arrays. Their values can be any scalar type and objects of known classes. Nested arrays are not supported currently. Since the declaration is uniform in C++ (all members of an array must be of the same type), all members of a Ruby array must be convertible to the target type.
Pointers and references are a special topic for C++ to Ruby binding. Ruby does not have the concept of a reference. Instead, all object values are references by definition. RBA can convert between Ruby variables and pointers/references and also supports "out" parameters.
"void" as return value
While a "void" return value indicates "no return value" in C++, this concept is not common in Ruby. Ruby methods will always return the last value generated in a method.
For consistency, KLayout's Ruby binding returns "self" from methods in this case. This allows chaining of methods in many cases and fosters compact code:
// C++
class A {
public:
virtual void f() { ... }
virtual void g() { ... }
};
# Ruby
a = A::new.f.gReferences and pointers to simple types (FixNum, Float, String)
Simple types can be passed as values to arguments expecting pointers and references. RBA will convert the value to a pointer to that value and pass that pointer to the method. Pointer arguments also support the "nil" value which is converted to a null pointer. Beware that not all C++ methods expecting a pointer argument are aware of null pointers and may have trouble digesting that value.
Often, (non-const) reference and pointer arguments are used as "out" parameters, i.e. the method alters the value of the memory location passed by the pointer value. That imposes a problem for the Ruby binding: since Ruby does not pass references for simple types, the value of a variable cannot be altered and the following code does not work as expected:
// C++: use x as an "out" parameter:
void A::f(int &x) { x = 5; }
# Ruby:
x = 1
A::new.f(x)
# x is NOT 5!RBA solves that problem by providing a "boxing" mechanism: a value is stored inside an object which is passed by reference. RBA provides the class Value for that purpose. This class serves as a container for any type and can be used to solve the "out" parameter problem this way:
// C++: use x as an "out" parameter:
void A::f(int &x) { x = 5; }
# Ruby:
x = RBA::Value.new(1)
A::new.f(x)
# x.value is 5 nowThe RBA::Value object has a attribute "value" which can hold any type. RBA will convert that member into the value required by the method's argument. The method will receive a pointer or reference to that value and can modify that memory location. After the method has returned, the modified value can be accessed by reading the "value" attribute.
Reference and pointer return values are simply converted to copies of the value.
Special pointers: const char *, void *
"const char *" pointers are mapped to Ruby strings. The same is true for "const unsigned char *". The non-const versions "char *" and "unsiged char *" are somewhat ambiguous and are mapped to strings currently.
"void *" is mapped to an integer value representing the address the pointer points at. Since it is not possible to address a value by a pointer in Ruby as well as getting the address of a value, there is noch much use for the "void *" values expect if those values are delivered and digested by C++ methods. This is the case for some "handle" values (i.e. Windows object handles) and some cases, where "void *" stands for "some arbitrary value which can be a pointer or an integer".
Pointers as arrays
In "C style" C++, pointers are sometimes used as the start position of an array and point to a number of items, not only one. Usually there is another parameter telling the number of items the pointer points to. Since there is no declaration for that kind of calling convention, the Ruby binding cannot support that case. Only "char *" and "const char *" are supported and it is assumed that arguments of these type expect a zero-terminated byte string in UTF-8 encoding.
Fortunately that case is rare. Specifically the Qt API uses references to QByteArray, QVector, QList and similar container classes which can be mapped to Ruby arrays.
References and pointers to complex types
References and pointers to complex types and objects of Ruby classes for which a C++ class exists are simply converted to pointers or references to the C++ class. Pointer arguments can also be passed "nil" which renders a null pointer. Again, not all method implementations may be prepared for that value and the application may crash in that case.
Hash arguments and return values
Associative containers (std::map, QHash etc.) are mapped to Ruby hashes. Unlike Ruby, C++ associative containers are strictly typed, so it's important to provide the right key and value pairs.
Default arguments
Some functions provide defaults for certain arguments. If these arguments are omitted, the default value is used instead.
Keyword arguments
Starting with version 3, Ruby supports "real" keyword arguments. Keyword arguments are supported for most methods with the exception of a few built-in ones such as "assign". Keyword arguments can be used when the other, non-optional arguments are given either by positional arguments or other keyword arguments.
Keyword arguments are somewhat more expressive and allow a shorter notation. For example, to instantiate a 45 degree rotation, you can write:
t = RBA::CplxTrans::new(rot: 45)
Implicit conversions
String arguments
If a method expects a string argument, other types are converted to strings using the "to_s" method. In Python, the equivalent is "str(...)".
Example:
# Also accepts a float value for the first string argument - # it is converted to "2.5" t = RBA::Text::new(2.5, RBA::Trans::new)
Conversion constructors
Conversion constructors are constructors that take an object of a different class and convert it to the target class. Conversion constructors are used implicitly in applicable cases to convert one type to the type requested by the argument.
For example, in the following code, the Region object's "+" operator is used. This expects a Region object as the second parameter, but as there is conversion constructor available which converts a Box to a Region, it is possible to use a Box directly:
r = RBA::Region::new(RBA::Box::new(0, 0, 1000, 2000)) r += RBA::Box::new(3000, 0, 4000, 2000)
Implicit constructor from lists
When an object is expected for an argument and a list is given, the object constructor is called with the arguments from the list. This specifically allows using size-2 lists instead of Point or Vector arguments. In Python, a "list" can also be a tuple.
In the following example, this mechanism is used for the polygon point list which is expected to be an array of Point objects, but can use size-2 arrays instead. Also, the "moved" method expects a Vector, but here as well, size-2 arrays can be used instead:
pts = [ [ 0, 0 ], [ 0, 1000 ], [ 1000, 0 ] ] poly = RBA::Polygon::new(pts) poly = poly.moved([ 100, 200 ])
Constness
C++ has the concept of "constness". That means that if a pointer or a reference to an object is declared "const", the object cannot be modified. Also, methods can be declared "const" meaning that such methods do no alter the (externally visible) state of an object. C++ ensures constness, because it only allows calling of const methods on const references of objects.
The concept of constness is part of the contract between a caller of a method and the method's implementation: if a method declares an argument to be a const reference or pointer, it tells the caller that it will not modify the object. Similar, returning a const reference is a safe way to expose internal objects because the implementor of the method can be sure that code outside a method will not modify the state of the object returned. Thus, constness is a vital part of a contract and somehow needs to be mapped in the Ruby binding.
Unfortunately that is not as easy as it may look. The problem is basically that Ruby does not have the concept of constness, but it has references. Remember that there is always a pair of Ruby/C++ objects. When a reference to a C++ object is returned into Ruby space, the Ruby counterpart of the object is created and a reference to that object is returned.
But where do we have to attach the constness of the reference? The answer is that there is no other place except the Ruby object. Hence, if a const reference is returned, a "const Ruby object" is created. That object will refuse to execute non-const methods. That way, the const semantics is maintained.
Trouble starts when another non-const reference is returned to the same object. In that case, the Ruby object needs to be reused but this time with non-const semantics. That is a contradiction to the previous const state. RBA solves this issue by switching the object to non-const state in that case and will allow to call non-const methods after that.
In other words: constness is part of the object identity in Ruby and it can change. That actually makes some sense: when I obtained a const reference there may be another way to obtain a non-const reference. Once I have a non-const reference I can modify the object which also is behind the const reference. Thus keeping a const reference is no longer a safety feature and the const reference can be dropped.
To avoid lifetime issues, RBA does not work with references a lot. Objects returned by a const reference are always copied. Only const pointers are kept as const object references in Ruby.
Reimplementing Virtual Methods
The Ruby binding supports reimplementation of virtual C++ methods in derived classes. This works as expected:
// C++
class A {
public:
virtual void f() { }
};
# Ruby
class B < A
def f
# f is called when A::f is called on the C++ side
end
endVirtual methods are often used as callbacks and provide a reverse call path from C++ to Ruby:
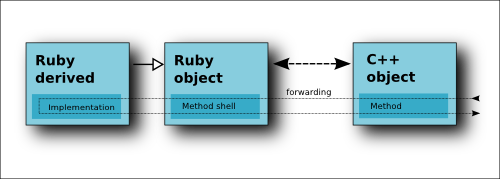
The parameters of the Ruby implementation must match the parameters of the C++ method. Mapping of Ruby to C++ types applies to the Ruby method arguments the same way than for return values of ordinary methods. Virtual functions can also return values. In that case the same mapping rules than for ordinary method arguments apply.
Iterators
A special feature of KLayout's Ruby binding are iterators. C++ iterators are mapped to Ruby iterators. For example:
// C++
class A {
public:
// begin()..end() are mapped to the "each" method in Ruby:
iterator begin();
iterator end();
};
# Ruby
a = A::new
a.each { |i| ... }If no block is given, an Enumerator object is created. Enumerators are a Ruby feature. Enumerators support many convenient methods like sort, inject, collect, select etc. Here is an example:
# turns all elements returned by the iterator into strings and sorts them sorted = a.each.collect(&:to_s).sort
Iterators match very well between C++ and Ruby so there are no real issues here. The return type of the iterators is mapped to Ruby's block arguments using the same rules than for values returned from C++ methods.
Exceptions
Raising an error in Ruby is a valid way to terminate the execution of the method. A Ruby error is mapped to a C++ exception which usually is caught in the C++ code and handled properly. There are some cases, where raising an exception can crash the application. That is the case in particular in event handlers of Qt objects. Usually, raising an exception is safe.
Events
Events are a special feature of KLayout's Ruby binding. Events are similar to reimplementations of virtual functions except that no derived class is required and the call is handled by a Ruby block. Events can have return values but using "return" inside a block does not have the expected effect. Instead, the value of the last expression in the block is used. That is a feature of Ruby, not a speciality of RBA.
There is always one receiver for an event. If a new block is assigned to an event, the old block will no longer be called. Here is an example of using events:
// C++
class A {
public:
// e is an event with an integer argument
void f(i) { e(i); }
};
# Ruby
a = A::new
a.e { |i| puts i; }
a.f(15) # calls the block attached to e with the argument 15Events are extensively used for an alternative to Qt slots. The Qt binding of KLayout maps every signal to an event. That means, that it is possible to connect a block to a Qt signal directly at the sender object without having to create a receiver. For example:
# Ruby
b = RBA::QPushButton::new
# print a message, when the button is clicked
b.clicked { puts "Ouch." }There is one significant difference between Qt signals and events: A Qt signal can have many receivers while an event always has one block which is executed when the signal is emitted. Connecting signals and slots still is supported with the "connect" method, but it is not possible to define slots on Ruby methods. The events fill that gap and, in the authors opinion, in a much more convenient way.