Howdy, Stranger!
It looks like you're new here. If you want to get involved, click one of these buttons!
Quick Links
instancing based on a list of coordinates and angles

Hi all,
I am trying to generate a layout where an instance is populated based on a list of coordinates and angles. For instance the design would read a .csv file by a script in the macro development platform of KLayout where the details of the design are stored in three columns such as;
x, y, theta
Does anyone have experience in generating such layouts based on a coordinates and angles list?
Any help is much appreciated.
Thanks
klaybur
Comments
Hi klaybur,
How about this PYA example?
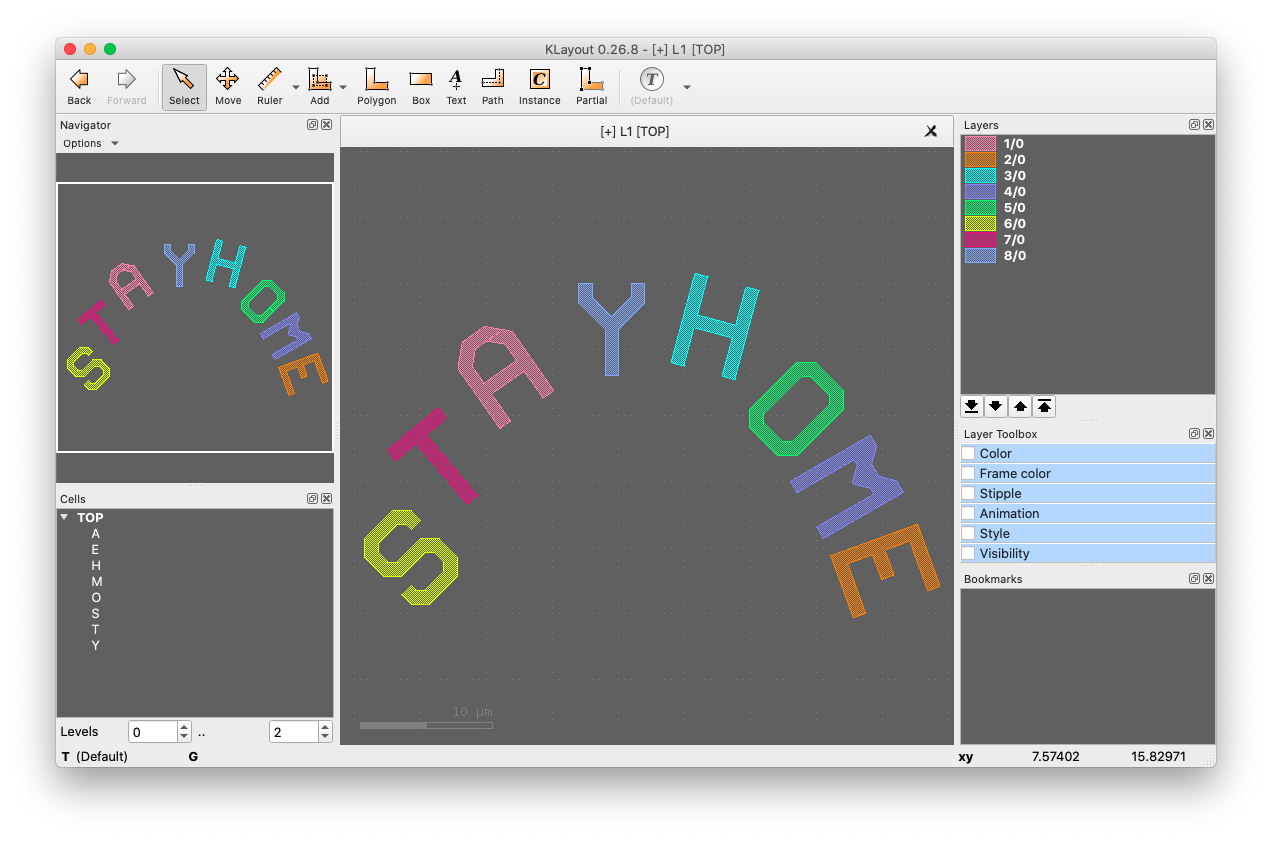
Kazzz-S
Hi Sekigawa,
This is great. Thank you very much. I can confirm that I could run the script and it is actually achieving more than what I need")
What I would like to be able to do is use an existing cell and apply the coordinates and angles defined in the .csv file to a sub-cell under the newly generated cell which is named "TOP".
I attached to this message a .gds file that includes a cell "TEST" that just has a 20um square box in it. (this would serve as the sub-cell). Attached is also a .py file where I tried to modify the initial script that you shared in order to achieve my abovementioned goal of instancing the "TEST" cell based on the coordinates and angles given .csv file.
The script that I run is quite rough and gives errors as I am missing some python commands to select a current cell and populate it based on the .csv file and I would appreciate if you could help debug the attached file.
Thanks again for your time.
Regards
klaybur
Hi,
I wanted to follow up on my previous message with another comment.
Another option to achieve angles and coordinates based instancing, I believe, can be by modifying the ruby script in the link below;
https://www.klayout.de/forum/discussion/comment/6824#Comment_6824
I tried to modify the existing code in the above link by;
a) introducing another column which refers to the angle in the reference .txt file
b) introducing
CplxTranscommand rather thanTransbut clearly I am missing something as the code gives error. The details of my attempt to modify the above code can be also seen below.
Any help/comments most welcome.
Thanks
klaybur
Hi klaybur,
From the above-attached files, I could get a clear idea about what you want to do.
Please refer to the files in the attached ZIP file. The modified PYA is KazzzS-2809_Coord_Angle.py.
I believe the new script is more in-line with your requirements.
Kazzz-S
Hi Sekigawa,
Thank you very much for your quick reply. Indeed the new script achieves what I would like to do. I am also going through your comments which I find very useful.
There is one issue I am having though which I would like to check, too. It looks like whenever I modify the csv file I run into the error message below. My suspicion is that when I save the new file the computer somehow modifies it that is not transparent to me and the python script can't read it anymore, but I would appreciate if you have any comments on this issue as well.
P.S. I tried to remove some of the rows from the list, change x coordinates or y coordinates and always ran into the same error.
Thanks
klaybur
Hi Sekigawa,
Sorry for multiple comments, but I think I understand the issue.
I tried to edit the file in wordpad and ensured that it was ANSI encoded when replacing the existing .csv file. After this I could modify the coordinates without the error in my previous comment.
Thanks again for your help
klaybur
Hi klaybur,
Nice to hear that the new script serves for you.
About one hour after submitting the No.2 ZIP file, I revised some source code comments and reattached the ZIP.
Please update with the present one. Sorry for the inconvenience caused.
Kazzz-S
Hi klaybur,
I should have mentioned about the [Ignore] option in debugging even though you may know about it.
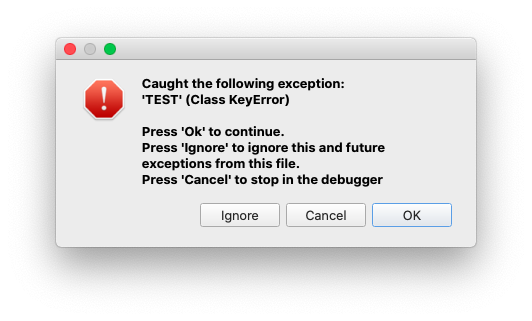
If we choose this option, the debugger does not stop on the exception.
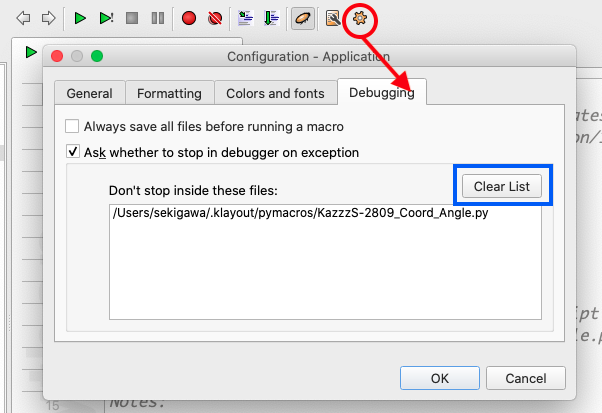
This option is convenient if we have two or more kinds of sub-cells in the CSV.
We can reset this setting from the dialog below.
Another updated script is attached.
Kazzz-S
I am delighted to see this discussion going this far and deep!
Thanks a lot!
Matthias
Hi Sekigawa,
Sorry for the belated reply and thanks again for useful comments. I noticed the error in your message, too and clicked 'ok' or 'ignore' buttons to carry on. The script worked, but I will try to follow your suggestion to change debugging settings, too. On a separate note, may I ask why the 'TEST' cell comes as an exception error?
Regards
klaybur
Hi klaybur,
Regarding the "exception," let's examine the code "KazzzS-2809_Coord_Angle.py" line-by-line.
A corresponding line number is indicated by
[L-nnn].To start with, our script does not know anything about "what to layout and how."
In our design idea, we keep such info in the "2809_Coord_Angle.csv" CSV file.
[L-56]We search the CSV file for "what to layout and how," and store the information into a dictionary (a vital object in Python)
layDic.Note that this dictionary is EMPTY initially.
[L-57]With the Pandas module, we read the CSV file in one-shot and construct a DataFrame.
A DataFrame is one of the core data structures provided by Pandas module.
We can interpret a DataFrame as an Excel sheet.
While reading a CSV file, lines starting with '#' are considered as comments and ignored.
One column label line, if any, is intelligently inferred.
We can embed any descriptive words and one column label line in a CSV file thanks to these features.
By default, the Pandas module assumes that a CSV file is in UTF-8 encoding.
[L-58]~[L-62]Now that we have one Excel-sheet-like object, we can visit any Excel-cell at random.
[L-58]however, let's traverse it row-by-row.* len(df) delivers total number of rows (excluding the comment lines and the column label line).
* with df.iloc[idx, p], we can access (row-idx, column-p); hence, at random basically.
* more precisely,
df.iloc[idx, 0] ==> ChildCell ( .strip("'") strips off single quotation marks )
df.iloc[idx, 1] ==> X[um]
df.iloc[idx, 2] ==> Y[um]
df.iloc[idx, 3] ==> Angle[deg]
Just after
[L-62]We have obtained the FIRST particular child cell name="TEST" (what) and its X[um], Y[um], and Angle[deg] (how).
[L-64]It's time to insert the FIRST what-how pair into the dictionary.
Before that, we ask the dictionary whether the particular cell name already exists in the dictionary, a 'YES' or 'NO' question.
If the answer is 'NO,' instead of saying so, a dictionary throws an exception (KeyError, in this case),
which is a fundamental behavior of a dictionary.
If we do not catch and care an exception appropriately, our program crashes.
Back to
[L-63]~[L-69]These lines construct a "try ~ except ~ else" clause (refer to a good Python textbook).
[L-64]in the FIRST query, the answer must be 'NO' because the dictionary is EMPTY[L-65]hence, we get a KeyErrorbut the debugger catches it before us by default and asks us what to do.
[L-66]clicking[OK], we take care of it by inserting the FIRST info to the dictionary as a list object[L-67]and continue to the next entryIn the second query and beyond with the same key ("TEST"), the answer must be 'YES' because the dictionary knows that key.
[L-64]has already returned the existing value totupleList(as a list object)[L-68]here, else: means 'if the key is already existing in the dictionary...''[L-68]append the new info to the existing one held bytupleListand update the dictionary contentsThese are steps on how the dictionary stores the multiple layout condition for the "TEST" cell.
When we run the script in the IDE window, the exception trap dialog pops up only once because we have one key, "TEST" in the CSV file.
However, if we try to layout five different cells such as [TEST]x8, [A]x10, [B]x1, [C]x20, [D]x30,
the dialog pops up five times and interrupts the code execution at the first appearance of a new-comer, which is annoying.
The
[Ignore]option is to suppress this because we know this exception is harmless, and our code takes care of it.I hope my explanations are understandable to you.
BTW, a question from my side:
Do you think what would happen, or what we should do, if the CSV file contains duplicated lines by overlooked edit errors?
Inspired by your post, I came up with such a tutorial problem for my junior colleagues.
I'll share it with you once it's ready.
Kazzz-S
Hi klaybur,
I've attached the tutorial.
Just for your reference.
Kazzz-S